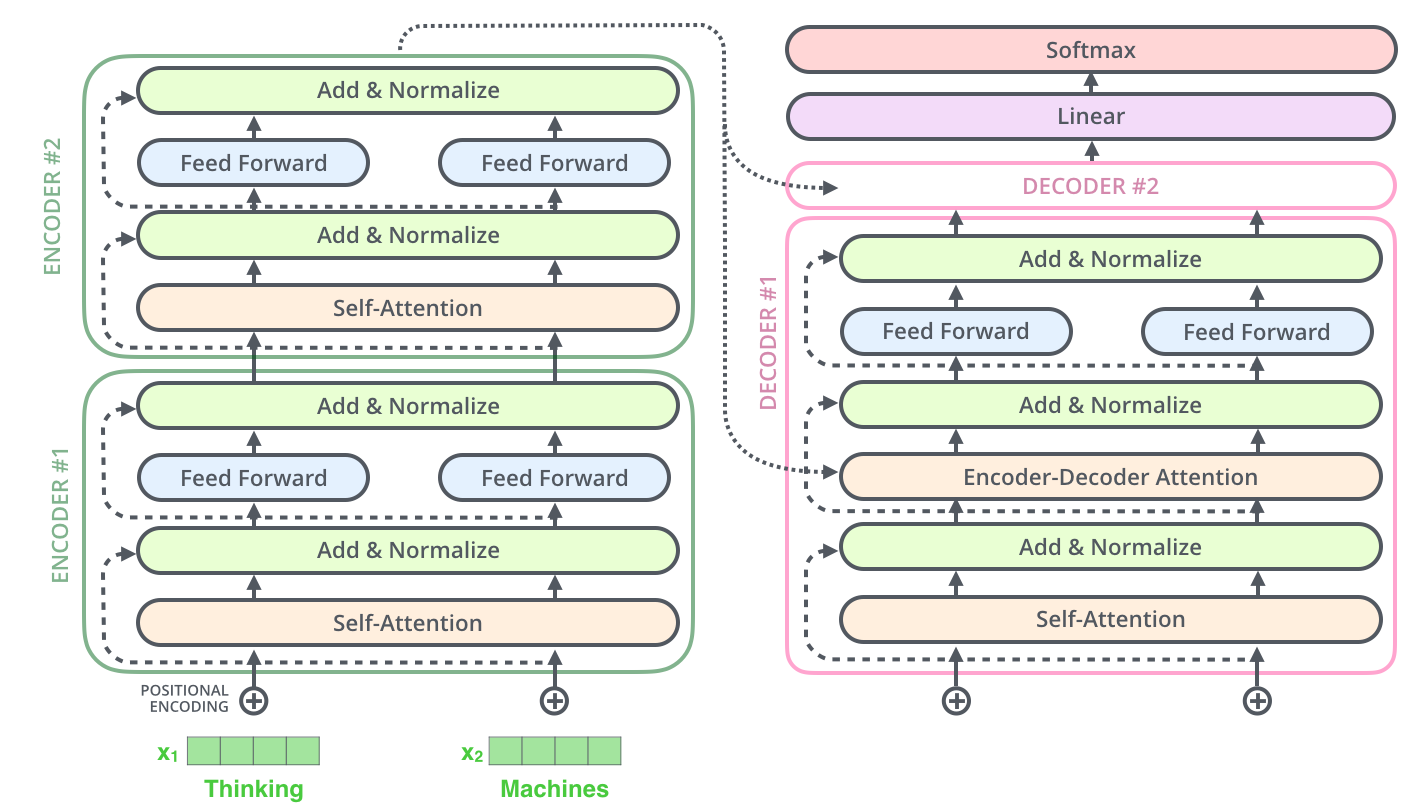
论文《Attention is All You Need》中关于original Transformer的理解
推荐一个非常棒的Transformer博客
Transformer的理解整体架构上是有encoder和decoder两个部分构成。
原文中的encoder和decoder都有6层,这里的层是纵向上的叠加,层数的加深就是指很多个self-attention。
N代表的是多个抽头,抽头是横向上的叠加。多个抽头的作用使得一个单词得到句子不同的关注重心。
除了self-attention,结构中该包括了Residual block(跳跃连接,由f(x)变为f(x)+x)/Normalize(正则化)/Feed forward(维度缩放)等具体实现。
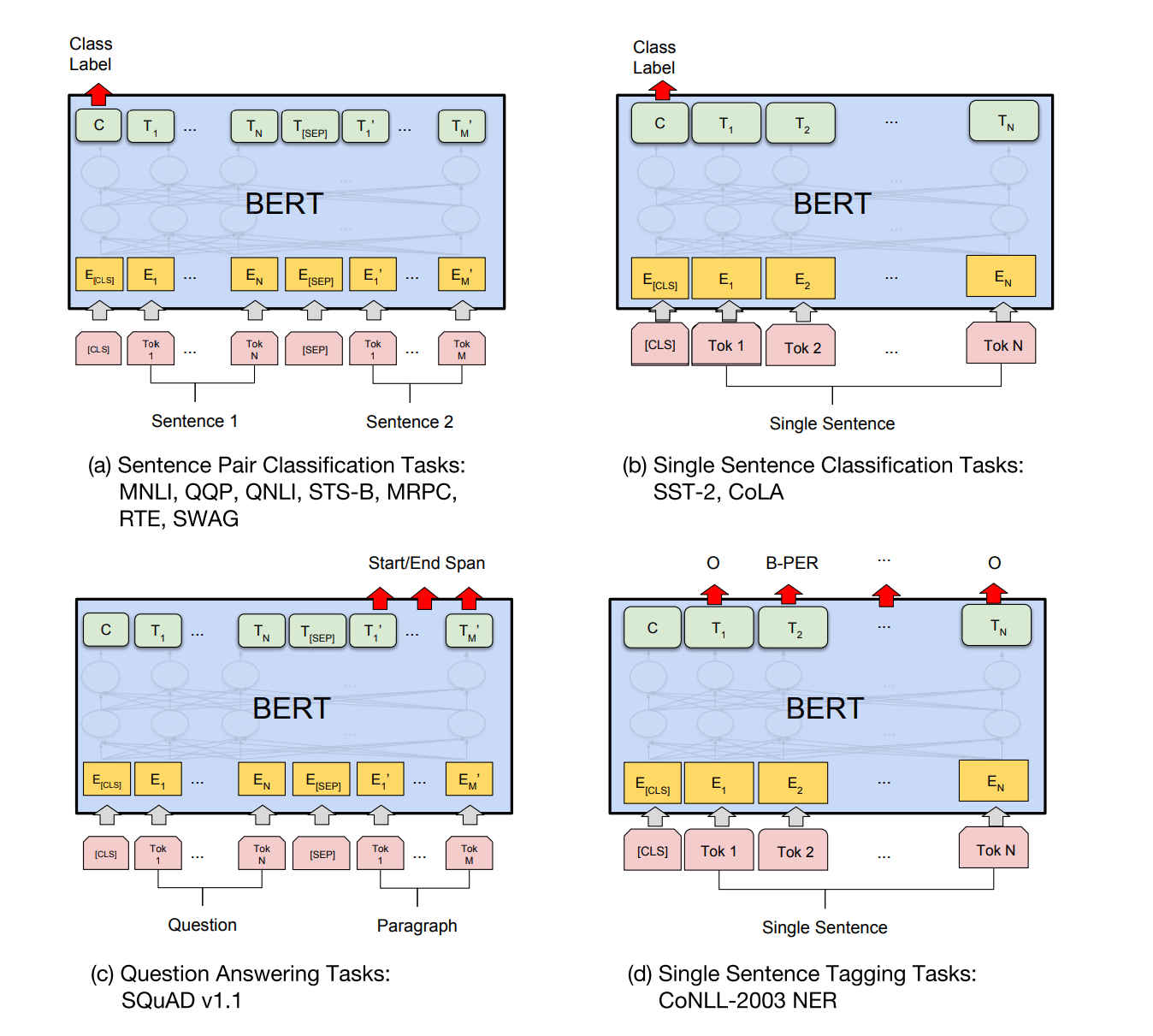
论文《BERT》中关于Transformer的理解
Transformer结构中编码解码的方向依赖是不一样的,解码时候每个单词会与所有单词产生联系,但是解码的时候一个单词只会与其左边的单词产生关联
| Transformer结构 | 方向 |
|---|---|
| Transformer encoder | bidirectional |
| Transformer decoder | left-context-only |
为了使用双向结构,BERT中所涉及的Transformer其实是Transformer encoder。
这个在bert/modeling/transformer_model代码实现中有注释: This is almost an exact implementation of the original Transformer encoder.
Transformer_block in codes(BERT_base)
| 参数名 | 数值 | 含义 |
|---|---|---|
| num_hidden_layers | 12 | Number of hidden layers in the Transformer encoder |
| hidden_size | 768 | Size of the encoder layers and the pooler layer |
| num_attention_heads | 12 | Number of attention heads for each attention layer in the Transformer encoder |
| hidden_act | glue | We use a gelu activation (Hendrycks and Gimpel, 2016) rather than the standard relu, following OpenAI GPT. |
# BertModel相关参数设置与相关解释
def __init__(self,
vocab_size,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
initializer_range=0.02):
"""Constructs BertConfig.
Args:
vocab_size: Vocabulary size of `inputs_ids` in `BertModel`.
hidden_size: Size of the encoder layers and the pooler layer.
num_hidden_layers: Number of hidden layers in the Transformer encoder.
num_attention_heads: Number of attention heads for each attention layer in
the Transformer encoder.
intermediate_size: The size of the "intermediate" (i.e., feed-forward)
layer in the Transformer encoder.
hidden_act: The non-linear activation function (function or string) in the
encoder and pooler.
hidden_dropout_prob: The dropout probability for all fully connected
layers in the embeddings, encoder, and pooler.
attention_probs_dropout_prob: The dropout ratio for the attention
probabilities.
max_position_embeddings: The maximum sequence length that this model might
ever be used with. Typically set this to something large just in case
(e.g., 512 or 1024 or 2048).
type_vocab_size: The vocabulary size of the `token_type_ids` passed into
`BertModel`.
initializer_range: The stdev of the truncated_normal_initializer for
initializing all weight matrices.
"""
BERT相关的两个预训练任务之Masked Lauguage Model
代码参见
https://github.com/google-research/bert/blob/4e2e06ab43/create_pretraining_data.py / def create_masked_lm_predictions
将一个句子中某些单词抠掉(mask),其中抠的比例为15%。不过嘛,抠是俗话,真正的做法是随机替换句子中的词为[MASK]。不过因为在fine-tune阶段不会看到这个人工标记[MASK],所以有必要做些工作能在fine-tune时适应这个模型:不再将要抠的词全部替换为[MASK],只抠80%,还有10%随机替换为其他词,还有10%直接不动。
句子处理之后带入模型,要求预测被抠掉的那些词(包括那10%被选中但是没有替换的单词也要预测)。
instance = TrainingInstance(
tokens=tokens,
segment_ids=segment_ids,
is_random_next=is_random_next,
masked_lm_positions=masked_lm_positions,
masked_lm_labels=masked_lm_labels)
BERT相关的两个预训练任务之Next Sentence Prediction
这个任务主要是使得BERT可以适应两个句子关系的相关任务。
当要选择两个句子的时候,句子B有50%可能性是句子A的下一句,有50%的可能性是语料库中随机抽取的。
句子通过[CLS]+句子A+[SEP]+句子B+[SEP]完成拼接带入训练模型。最后一层的[CLS]中蕴含了整个句子的信息。
BERT联合训练
Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
BERT关于上述的两个任何是同时进行训练的
https://github.com/google-research/bert/blob/4e2e06ab43/run_pretraining.py
(masked_lm_loss,
masked_lm_example_loss, masked_lm_log_probs) = get_masked_lm_output(
bert_config, model.get_sequence_output(), model.get_embedding_table(),
masked_lm_positions, masked_lm_ids, masked_lm_weights)
(next_sentence_loss, next_sentence_example_loss,
next_sentence_log_probs) = get_next_sentence_output(
bert_config, model.get_pooled_output(), next_sentence_labels)
total_loss = masked_lm_loss + next_sentence_loss
BERT的刷榜
- 句子对分类问题
- 单个句子分类问题
- 阅读理解(SQuAD v1.1)
- 单句子语言标注